
Time Complexity(시간 복잡도)
 |
알고리즘 문제는 해답을 찾는 것도 중요하지만, 그만큼 효율적인 방법으로 해결했는지도 중요하다
→ 효율성 = 시간 복잡도
시간 복잡도
알고리즘 문제에서 자주 겪게 되는 문제?
→ 바로, 시간 복잡도 그 의미는?
입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?
효율적인 알고리즘이란, 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 것
이러한 시간 복잡도는 빅-오 표기법으로 나타낸다
Big-O 표기법
시간 복잡도를 표기하는 방법은 아래의 3가지가 있으나 주로 빅-오 표기법을 사용한다
* Big-O(빅-오): 시간 복잡도를 최악의 경우에 대해 나타내는 방법
* Big-Ω(빅-오메가): 최선의 경우
* Big-θ(빅-세타): 중간(평균)의 경우
이 정도 시간까지 걸릴 수 있다(최악)의 시간까지 고려할 수 있기 때문
→ 최선이나, 평균의 경우만 고려했다면, 예상 시간보다 실제로 걸린 시간이 훨씬 오래 걸렸을 때 어디서 문제가 발생했는지 파악하는데 매우 많은 시간이 필요함
그러므로, 극단적인(최악의) 경우도 고려하여 대비하는 것이 바람직
O(1) 시간 복잡도
 |
O(1)는 constant complexity 라고 부른다(불변)
→ 즉, 입력 값이 증가하더라도 시간이 늘어나지 않는 경우임
→ 입력 값의 크기와 상관없이 즉시 출력 값을 얻어낼 수 있다는 뜻
// O(1)의 시간 복잡도를 가지는 알고리즘의 예
function O_1_algorithm(arr, index) {
return arr[index];
}
let arr = [1, 2, 3, 4];
let index = 1;
let result = O_1_algorithm(arr, index);
console.log(result); // 2
// 입력 값인 arr의 길이가 한없이 커지더라도 즉시 해당 index에 접근해 값을 반환 가능하다
O(n) 시간 복잡도
 |
O(n)은 linear complexity 라고 부르며, 이름 그대로 입력값 증가에 따라 시간 또한 같은 비율로 증가(선형)
// O(n)의 시간 복잡도를 가지는 알고리즘의 예
function O_n_algorithm(n) {
for (let i = 0; i < n; i++) {
// do something for 1 second
}
}
// 입력 값(n)이 1 증가할 때마다 코드 실행 시간이 1초씩 증가
function another_O_n_algorithm(n) {
for (let i = 0; i < 2n; i++) {
// do something for 1 second
}
}
// 입력 값(n)이 1 증가할 때마다 코드 실행 시간이 2초씩 증가위의 case에서 O(2n)이라고 생각할 수 도 있겠지만, 입력 값(n)이 한없이 커진다고 하면 앞이 2든 3이든 10이든, n에 수렴하게 될 것이다.
→ 즉, 계수의 의미(영향력)가 점점 퇴색되므로, 이 경우도 O(n)으로 볼 수 있다
O(log n) 시간 복잡도
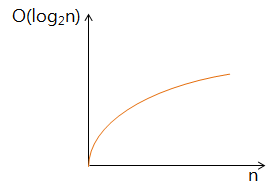 |
logarithmic complexity 라고 부르며, 빅-오 표기법 중 O(1) 다음으로 빠른 시간 복잡도를 가짐
→ 즉, 그래프를 보면 알겠지만, O(n) 보다 빠르다
대표적인 예로 BST(이진 탐색 트리)가 있다
→ 원하는 값을 탐색할 때, 노드를 이동할 때마다 경우의 수가 절반으로 줄어든다
(마치 술자리 up & down 게임처럼 말이다)
O(n^2) 시간 복잡도
 |
quadratic complexity 라고 부르며, 입력값이 증가함에 따라 시간이 n의 제곱수의 비율(n^2)로 증가하는 것을 의미
간단히 예로 설명하면, 입력값이 1일 때 1초가 걸리던게, 5의 입력값일 때는 25초(5^2), 9의 입력값일 때는 81초(9^2)가 걸리는 알고리즘
→ 2중 for문이 0(N^2)의 시간 복잡도를 가짐
// O(n^2)의 시간 복잡도를 가지는 알고리즘의 예
function O_quadratic_algorithm(n) {
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
// do something for 1 second
}
}
}
// n^2 만큼 시간이 증가
function another_O_quadratic_algorithm(n) {
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
for (let k = 0; k < n; k++) {
// do something for 1 second
}
}
}
}
// n^3 만큼 시간이 증가O(n)의 경우와 마찬가지로 n^3이든 n^5든, n이 한없이 커졌을 때를 보면, 결국 n에 수렴하게 되므로, 지수의 영향력이 점점 퇴색된다
→ 그러므로 O(n^2)라고 표기할 수 있다
O(2^n) 시간 복잡도
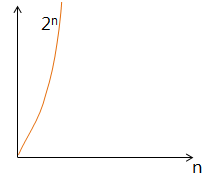 |
exponential complexity 라고 부르며, 빅-오 표기법 중 가장 느린 시간 복잡도를 가짐(가장 비효율적)
→ 입력값이 단 1이 증가할 때마다 시간은 2배로 증가한다
구현한 알고리즘의 시간 복잡도가 O(2^n)이라면 다른 접근 방식을 찾아 봐야 할 것이다
//O(2^n)의 시간 복잡도를 가지는 알고리즘의 예: 재귀로 구현한 피보나치 수열
function fibonacci(n) {
if (n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}시간 복잡도를 고려한 문제 파악하기
코딩 테스트에서는 정확한 값(원하는 출력값)을 제한된 시간 내에 반환하는 프로그램을 작성해야 함
→ 시간 제한과 데이터 크기 제한에 따라 시간 복잡도를 어림잡아 예측하는 것이 중요하다!
입력 데이터가 좀 크다 싶으면, 시간 복잡도를 O(n) 또는 O(log n)을 만족하도록 문제를 풀어야 함
주어진 입력 데이터가 작으면, 시간 복잡도가 크더라도 문제를 풀어 내기만 하면 된다(O(n^2)까진 가능할 수도?)
일반적으로 대략적인 데이터 크기에 따른 시간 복잡도는 다음과 같다
데이터 크기에 따른 시간 복잡도
데이터 크기 제한(입력 값) 예상되는 시간 복잡도
=================================================
n <= 1,000,000 O(n) 또는 O(log n)
n <= 10,000 O(n^2)
n <= 500 O(n^3)
-------------------------------------------------Q1.) 가장 빠른/느린 시간 복잡도는?
A1.) 가장 빠른 것은 O(1)이다. 항상 불변하는 시간 복잡도니깐(즉시 반환)
가장 느린 것은 O(2^n)이다. 단 1만 증가해도 2배씩 커지면서 아주 심각하게 시간이 증가한다
Q2.) 효율적인 알고리즘을 구성했다는 것은 무엇을 의미할까?
A2.) 입력 값에 증가에 따른 증가하는 출력 값 반환 시간의 증가를 최소화 한 것
Q3.) 시간 복잡도는 A와 B의 비례함의 어느 정도인지를 나타낸다. 여기서 A와 B란?
A3.) A= 입력값, B= 시간
Q4.) O(log n)이 O(n) 보다 항상 빠를까?
A4.) 아니다. 입력값이 1개인 경우 둘다 같이 1이니깐(이 경우, 빠른 건 아니고 동일함)
Q5.) 시간 복잡도에서 가장 느린 것은 O(2^n)이다?
A5.) 아니다. 더 느린 것들도 표현 가능하다. 예를 들면 O(n!) (팩토리얼) 같은 경우가 존재
greedy Algorithm(탐욕 알고리즘)과 implementation(알고리즘 구현 문제)
greedy Algorithm이란?
Greedy = 탐욕스러운, 욕심많은 의 뜻
→ 선택의 순간마다 당장 눈 앞에 보이는 최적의 상황만을 쫒아 최종적인 해답에 도달하는 방법
탐욕 알고리즘의 기본 문제 해결 방식은 다음과 같다
1. 선택 절차(Selection Procedure): 현재 상태에서의 최적의 해답을 선택
2. 적절성 검사(Feasibility Check): 선택된 해(답)가 문제의 조건을 만족하는지 검사
3. 해답 검사(Solution Check): 원래의 문제가 해결되었는지 검사하고, 해결되지 않았다면 선택 절차(1)로 돌아가 위의 과정을 반복가령, 편의점 알바할 때 거스름돈 거슬러 주는 것을 생각하면 이해하기 쉽다
→ 4040원 물건에 대해 5000원을 받고 960원 거슬러 주기
→ 500원 1개, 100원 4개, 50원 1개, 10원 1개의 순서대로 거슬러 준다
정리하자면, 탐욕 알고리즘은 문제를 매결하는 과정에서 매순간 최적이라 생각되는 해답(locally optimal solution)을 찾으며, 이를 토대로 최종 문제의 해답(globally optimal solution)에 도달하는 문제 해결 방식
그런데 탐욕 알고리즘은 항상 최적의 결과를 보장하지는 못한다 는 단점이 존재
탐욕 알고리즘을 적용하려면 해결하려는 문제가 다음의 2가지 조건을 만족해야 한다
* 탐욕적 선택 속성(Greedy Choice Property): 앞의 선택이 이후의 선택에 영향을 주지 않는다
* 최적 부분 구조(Optimal Substructure): 문제에 대한 최종 해결 방법은 부분 문제에 대한
최적 문제 해결 방법으로 구성된다
탐욕 알고리즘은 항상 최적의 결과를 도출하는 것은 아니지만, 최적에 근사한 값을 빠르게 도출 가능
→ 근사 알고리즘
알고리즘 구현(implementation) 문제
알고리즘 문제 풀기는 내가 생각한 로직을 코드로 구현한다는 것
→ 문제 해결을 코드로 풀어낼 때, 정확하고 빠를 수록 구현 능력이 좋다고 말한다
→ 구현 능력이 좋은 개발자를 기업이 선호
구현 문제(구현 유형): 본인이 선택한 프로그래밍 언어의 문법을 정확히 알고, 문제의 조건에 전부 부합하는 코드를 실수 없이 빠르게 작성을 하는 것(집중력, 끈기!)
→ 구현 능력을 보는 대표적인 예: 완전 탐색과 시뮬레이션(simulation)
- 완전 탐색: 가능한 모든 경우의 수를 전부 확인하여 문제를 푸는 방식
- 시뮬레이션: 문제에서 요구하는 복잡한 구현 요구 사항을 하나도 빠트리지 않고 코드로 옮겨, 마치 시뮬레이션을 하듯이 푸는 것
완전 탐색
모든 알고리즘 문제는 완전 탐색으로 풀 수 있다. 단순 무식한 방법이지만 무조건 답이 있다는 것!
→ 그런데 문제 해결은 할 수 있지만, 효율적으로 동작하지는 않을 수 있다는 단점 존재
완전 탐색은 단순히 모든 경우의 수를 탐색하는 모든 경우를 통칭한다.
→ brute force(무차별 대입; 조건/반복을 사용하여 해결), 재귀, 순열, DFS/BFS 등이 존재
//brute force의 예
// 편식하는 음식이 있으면 그 앞 뒤로 먹지 않고(좋아하는 음식이라도),
//좋아하는 음식만 먹을때, 각각의 아이가 먹는 음식의 수를 카운트
for(let i = 0; i < 100; i++) {
if(첫째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
if(둘째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
if(셋째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
}
return 많이 먹은 아이;반복문이 아닌 배열 메서드나 코드 간결화한 문법을 사용하더라도 배열을 전부 탐색하여 값을 도출한다는 것은 동일함
시뮬레이션
모든 과정과 조건이 문제에서 제시되어, 그 과정을 거친 결과가 무엇인지 확인하는 유형
보통, 문제에서 설명해 준 로직 그대로 코드로 작성하면 되지만, 그 내용이 길고 자세해서 코드로 옮기기 까다로운 특징!
→ 문제에 대한 이해를 바탕으로 제시하는 조건을 하나도 빠짐없이 처리해야 정답
Dynamic Programming(DP; 동적 계획법)
탐욕 알고리즘과 같이 작은 문제에서 출발한다
그러나 탐욕 알고리즘이 매 순간 최적의 선택을 찾는 방식인데 반해, DP는 모든 경우의 수를 조합해 최적의 해법을 찾는 방식이다
- DP의 원리
주어진 문제를 여러 개의 하위 문제로 나누어 풀고, 하위 문제들의 해결 방법을 결합하여 최종 문제를 해결하는 문제 해결 방식
→ 하위 문제를 계산한 뒤, 그 해결책을저장하고 나중에 동일한 하위 문제를 만나는 경우, 저장된 해결책을 적용해 계산 횟수를 줄인다.
즉, 하나의 문제는 단 1번만 풀도록 하는 알고리즘
DP는 다음의 조건들이 만족해야 사용 가능하다
1. 큰 문제를 작은 문제로 나눌 수(쪼갤 수) 있고, 이 작은 문제가 중복해서 발견된다(Overlapping Sub-problems)
→ 큰 문제로부터 나누어진 작은 문제는 큰 문제를 해결할 때 여러 번 반복해서 사용될 수 있어야 함을 의미
2. 작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 같다.
즉, 작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다. (Optimal Substructure)
첫번째 조건(부분 문제의 반복)은 피보나치 수열을 예로 볼 수 있다
// 재귀 함수로 구현한 피보나치 수열의 예
function fib(n) {
if(n <= 2) return 1;
return fib(n - 1) + fib(n - 2);
}
// 1, 1, 2, 3, 5, 8...
//5번째 피보나치 수 fib(5)를 구하는 과정
fib(5)=fib(4)+fib(3)
fib(5)=(fib(3)+fib(2))+(fib(2)+fib(1))
...위와 같이 작은 문제의 결과가 큰 문제 해결을 위해 여러 번 반복하여 사용할 수 있을 때, 부분 문제의 반복이라는 조건을 만족함
→ 주어진 문제를 단순히 반복 계산이 아니라, 작은 문제의 결과가 큰 문제를 해결하는데 반복적 사용되어야 함!
두번째 조건(Optimal Substructure)이 이 것을 뜻한다고 볼 수 있다.
→ 주어진 문제에 대한 최적의 해법(Optimal solution)을 찾을 때, 주어진 문제의 작은 문제들(부분 문제)의 최적의 해법을 찾아야 하고, 이 작은 문제들의 최적의 해법을 결합하면 결국 전체 문제의 최적의 해법을 구할 수 있다는 뜻
재귀 + 메모라이징(recursion + memoization)
다이나믹 프로그래밍(DP)는 하위 문제의 해결책을 저장해 둔 뒤, 동일한 하위 문제가 나왔을 때 저장된 해결값을 사용함. 이때 결과를 저장하는 방법이 memoization
memoization: 컴퓨터 프로그램이 동일한 계산을 반복해야 할 때, 이전에 계산한 값을 메모리에 저장함으로써 동일한 계산의 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술
// DP를 적용한 피보나치 수열 알고리즘의 예(재귀+메모라이징)
function fibMemo(n, memo = []) { // 인자로 n과 빈 배열 memo를 전달
// 이미 해결한 하위 문제인지 찾아본다
if(memo[n] !== undefined) return memo[n];
if(n <= 2) return 1;
// 없다면 재귀로 결괏값을 도출하여 res 에 할당
let res = fibMemo(n-1, memo) + fibMemo(n-2, memo);
// 추후 동일한 문제를 만났을 때 사용하기 위해 리턴 전에 memo 에 저장
memo[n] = res;
return res;
}n 이 커질 수록 계산해야 하는 과정은 선형(linear)으로 늘어난다
→ 시간 복잡도(O(n))
만약, memoization을 쓰지 않고 재귀함수로만 구했으면 시간복잡도 (O(2^n))
위의 피보나치 수열에서 fib(7)을 구하기 위해 fib(6)을, fib(6)을 구하기 위해 fib(5)을 호출한다.
→ 위에서 아래로 내려가는 것 같은 방식
→ 큰 문제를 해결하기 위해 작은 문제를 호출한다고 하여, 이 방식을 Top-down 방식이라 부름
반복문+ 표 만들기(배열)(Iteration + Tabulation)
반복문과 배열을 이용한 DP 구현하는 방식
하위 문제의 결과값을 배열에 저장하고, 필요할 때 조회하여 사용하는 것은 전자의 방식과 동일
그러나, 반복문을 이용하는 방식은 작은 문제부터 시작하여 큰 문제를 해결해 가는 방식
→ Bottom-up 방식
(재귀를 사용하는 방식은 큰 문제에서 시작하여 , 작은 문제로 가며 문제를 해결하는 방식이다)
// DP를 적용한 피보나치 수열 알고리즘의 예(반북문+ 배열 저장)
function fibTab(n) {
if(n <= 2) return 1;
let fibNum = [0, 1, 1];
// n 이 1 & 2일 때의 값을 미리 배열에 저장해 놓는다
for(let i = 3; i <= n; i++) {
fibNum[i] = fibNum[i-1] + fibNum[i-2];
// n >= 3 부터는 앞서 배열에 저장해 놓은 값들을 이용하여
// n번째 피보나치 수를 구한 뒤 배열에 저장 후 리턴한다
}
return fibNum[n];
}
크롬 개발자 도구에서 함수 실행 시간 측정 방법
실행 환경에 따라 결과가 다를 수 있음을 유념!
var t0 = performance.now();
fib(50); // 여기에서 함수 실행을 시켜주세요
var t1 = performance.now();
console.log("runtime: " + (t1 - t0) + 'ms')Q1) Top-down과 Bottom-up의 소요시간을 비교하면 어떤 차이가 있고 원인은 무엇일까?
A1) 입력 값이 작을 때는 Top-down 방식이 더 빨랐고, 입력 값이 커질 수록 Bottom-up(반복문+저장) 방식이 더 빠른 결과가 나옴
Q2) 다이나믹 프로그래밍(DP)와 탐욕 알고리즘은 각각 어떤 경우에 사용하기 적합할까?
A2) 배낭 문제(Knapsack Problem)를 예로 들면, 배낭에 넣을 수 있는 물건을 쪼갤 수 있다면 greedy 알고리즘 가능
쪼갤 수 없다면(무게 등) DP 방식을 적용할 수 있다.
- 심화내용: 배낭 문제(Knapsack Problem)를 검색
코딩 테스트 tip
코딩테스트 난이도
일반적으로 프로그래머스 기준 레벨3, 해커랭크 기준 medium 정도 풀 수 있으면 코딩 테스트에 대한 압박감은 걱정하지 않아도 된다
→ 최소 프로그래머스 1단계는 수월하게 풀 수 있어야 한다
→ 코딩 테스트 어렵게 내는 기업은 4문제 중 1문제 꼴로 프로그래머스 3.5~4단계 / 해커랭크 hard 정도의 문제를 출제
단기간에 알고리즘 문제를 풀어야 한다면?
때로는 주입식 교육을 통해 알고리즘을 학습하는 것이 효과적일 수 있다
→ 많은 문제를 풀고, 유형에 대응할 수 있어야 함
→ 일부 코딩 테스트는 잘 알려진 유형들만 출제되고, 이 유형들을 접근하는 템플릿이 존재함
각종 코드 레퍼런스 관련 사이트: 레퍼런스 코드를 보고 빠르게 이해!
https://www.geeksforgeeks.org/
→ 백트래킹(backtracking), divide and conquer, graph 알고리즘
→ 이 3가지 문제에서 거진 출제되므로 이 것들을 꼭 정복하는 것이 중요하다!
GeeksforGeeks | A computer science portal for geeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
+ greedy(진짜 쉽거나 진짜 어렵거나), DP까지 알면 좋다!
Searching, Sorting 문제는 주어진 내장 함수를 쓰는 게 좋다
ex) Array.sort() 이런거
merge sort(병합 정렬),quick sort, heap sort 이런 거에 대해서는 설명할 수 있을 정도로 알면 될 듯
but, 알고리즘 공부할 시간이 많다면?
→ 레퍼런스 보지 않고 차근차근 문제를 푸는 게 가장 좋다(꾸준히 고민하여 하나씩 해결하는 게 BEST)
시간 복잡도
주어지는 대부분의 문제는 실행시간: 1초(보통 1억 번의 연산 당 1초)에 가깝게 디자인 되어 있다.
→ 1초가 걸리는 입력의 크기(외우는 게 좋다!) ← 대략적으로!
문제의 입력 값의 크기를 보고 어떤 시간 복잡도까지 써도 될지 생각할 수 있다!
O(n): 100,000,000 (1억)
O(N log n): 5,000,000 (500만)
O(n^2): 10,000 (1만)
O(n^3): 500
O(2^n): 26
O(n!): 11
Q) O(n^3) 알고리즘, 풀어야 할까? → for문 3중으로 쓴 case 같은?
A) 값이 작을 때(n<500)는 써도 되지만, 값이 크면 안 됨!
공간 복잡도
보통 시간 복잡도를 해결하면 공간 복잡도는 같이 해결되는 수준이다
Js에서 보통 변수 하나는 8 Byte(숫자)
→ 알고리즘 문제에 메모리 조건이 나올 수 있다
→ 일반적으로 128/256/512 가 자주 등장
공간 복잡도를 만족하지 못했다면, 쓸데 없는 배열이나 변수를 찾아서 지워주면 된다
문제를 처음 봤을 때?(when. 코딩 테스트)
1. 입력과 공간 상한을 확인
→ n이 몇이상 몇이하 인지 조건?, 공간 상한이 있다면 체크
2. 먼저, 완전 탐색으로 문제를 풀어본다; 단순 무식한 방법으로 문제를 이해!
→ 알고리즘이 바로 떠 올랐다면 그 알고리즘으로 풀어도 된다!
→ 문제에 순서를 부여한다. 가장 작은 거부터? 가장 큰 거부터 ? 풀 것인지
→ 배열 메소드를 쓰는 것 보단, 문제 풀이에 집중할 수 있도록 기본적인 반복문 사용을 추천
→ 간지고 뭐고, 통과만 하면 되므로...
3. 문제 푸는 시간의 30~50%는 문제를 분석하는데 사용해야 한다
→ 바로 코딩하기 보다는 하나씩 그려 가면서 분석하는 것(수도 코드)
기본적으로 알아둬야 할 유형(기출 유형)
외워야 하고, 코딩 테스트 직전에 보고 가면 좋다
1. GCD(최대 공약수, 최대 공배수)
→ 유클리드 호제법
2. 순열/조합
→ 엄청 자주 출제
→ 컴퓨팅 사고가 필요
3. 정렬은 Array.prototype.sort 사용하기
→ 제일 빠르게 문제 해결 가능(시간 절약)
4. DFS(재귀 사용), BFS(queue 사용)
→ 스택, 큐를 잘 알고 있고 이를 바탕으로 그래프를 그릴 수 있어야 함
→ 템플릿이 존재하므로 템플릿을 참고하자
5. 분할 정복(divide and conquer; 재귀 사용), DP(동적 프로그래밍)
→ 감을 잡기가 힘드므로, case study가 필요!
→ 레퍼런스 참고하면서 열심히 익혀야 함!
'SE Bootcamp 내용 정리' 카테고리의 다른 글
| 자료구조/알고리즘 - 정규표현식 (0) | 2021.11.11 |
|---|---|
| 자료구조/알고리즘 - 코딩 테스트 2 (0) | 2021.11.11 |
| SECTION 2 회고 (0) | 2021.11.08 |
| Linux - 사용 권한과 환경변수 (0) | 2021.11.08 |
| 클라이언트 빌드와 배포 (0) | 2021.11.08 |