
컴퓨터 공학 – 기초
컴퓨터 운영체제의 이론적인 지식들을 알아보자
학습 목표
* 프로그램, 프로세스, 스레드에 대한 기본적인 개념
- 동시성과 병렬성의 차이
- 자바스크립트 엔진(v8)의 특징
* 프로그래밍에서 문자열을 다루는 방법과 유니코드 및 인코딩
* 비트맵 이미지와 벡터 이미지의 차이
* 가비지 컬렉션
* 웹 서비스에서 사용하는 캐싱 기법과 종류
문자열과 그래픽(이미지)
문자열
2010년도 이후, 유니코드로 인코딩 방식이 통일화되었다고 보면 된다
유니코드
유니코드(Unicode)는 유니코드 협회(Unicode Consortium)가 제정하는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
→ 문자 집합, 문자 인코딩, 문자 알고리즘 등을 포함하는 개념
- 인코딩(부호화)
어떤 문자나 기호를 컴퓨터가 이용할 수 있는 신호로 만드는 것( ↔ 디코딩)
→ 이를 위해서는 미리 정해진 기준으로 입력과 해독이 처리되어야 하는데, 이 국제 표준이 유니코드
ASCII 문자
영문 알파벳을 사용하는 대표적인 문자 인코딩으로 7 비트로 모든 영어 알파벳을 표현
→ 유니코드는 ASCII를 확장한 형태
UTF-8 과 UTF-16
UTF-8과 UTF-16은 인코딩 방식의 차이를 의미
UTF-8은 Universal Coded Character Set + Transformation Format – 8-bit의 약자로, UTF- 뒤에 등장하는 숫자는 비트(bit)
UTF-8의 특징
- 가변 길이 인코딩
UTF-8은 유니코드 한 문자를 나타내기 위해 1 byte(= 8 bits)에서 4 bytes(32비트)까지 사용
네트워크를 통해 전송되는 텍스트는 주로 UTF-8로 인코딩됨
→ 사용된 문자에 따라 더 작은 크기의 문자열을 표현할 수 있기 때문
UTF-8은 ASCII 코드(주로, 영어 알파벳)의 경우 1 byte, 크게 영어 외 글자는 2byte, 3byte(한글), 보조 글자는 4byte를 차지. 이모지는 보조 글자에 해당하기 때문에 4byte가 필요
- 바이트 순서가 고정됨
UTF-16에 비해 바이트 순서를 따지지 않고, 순서가 정해져 있다
UTF-16의 특징
- 코드 그대로 바이트로 표현 가능
- 바이트 순서가 다양함(순서에 따라 종류가 달라짐)
UTF-16은 유니코드 코드 대부분(U+0000부터 U+FFFF; BMP) 을 16 bits로 표현
→ 대부분에 속하지 않는 일부 기타 문자는 4bytes(32비트)로 표현하여, UTF-16도 엄격히 말하면 가변 길이이지만, 대부분은 2바이트로 표현한다는 것
U+ABCD라는 16진수를 있는 그대로 2진법으로 변환
→ 1010-1011-1100-1101
이 이진법으로 표현된 문자를 16 bits(2 bytes)로 그대로 사용하고 바이트 순서(엔디언)에 따라 UTF-16의 종류도 달라짐
UTF-8에서 3바이트이던 한글은 UTF-16에서는 2바이트를 차지
그래픽(이미지)
비트맵(래스터)과 벡터 이미지
* 비트맵(래스터)
- 기반기술: pixel 기반
- 특징: 사진과 같이 색상 조합이 다양한 이미지에 적합
- 확대: 확대에 부적합 → 픽셀이 깨짐(품질 저하)
- 크기(dimention)에 따른 파일 용량(file size): 크기가 클 수록 용량 많이 먹는다(큰 사이즈)
- 상호 변환(→ 벡터): 이미지 복잡도에 따라 벡터로 변환하는데 오래 걸림
- 파일 포맷: jpg, gif, png, bmp, psd 등
- 웹 사용성: jpg, gif, png 등이 많이 쓰임
→ <canvas> 태그를 이용해 표현
* 벡터
- 기반기술: shape(수학적 계산) 기반
- 특징: 로고, 일러스트 같이 제품에 적용되는 이미지에 적합
- 확대: 확대에 적합 → 품질 저하 없이 확대 가능하고, 해상도 영향을 받지 않는다
- 크기에 따른 파일 용량: 이미지 크기에 영향 받지 않는다(작은 사이즈 유지)
- 상호 변환(→ 비트맵): 쉽게 비트맵 이미지로 변환 가능(적은 시간 소요)
- 파일 포맷: svg, ai 등
- 웹 사용성: svg는 브라우저에서 대부분 지원
→ <svg> 태그를 이용해 표현
운영체제
운영체제 개요
하드웨어에게 일을 시키는 주체가 운영체제
운영체제(OS)
운영체제가 하는 일은 크게 다음과 같다
시스템 자원 관리
운영체제는 응용 프로그램이 하드웨어에게 일을 시킬 수 있도록 도와주는 역할
→ CPU, RAM, 디스크 등의 시스템 자원을 관리해 준다
- 프로세스(CPU) 관리
- 메모리(RAM) 관리
- I/O(입출력) 관리 (ex. 디스크, 네트워크, 프린터, 마우스 ...)
 |
응용 프로그램 관리
응용 프로그램이 내 시스템의 자원을 마음대로 사용하지 못하도록, 권한에 대한 관리가 필요함
→ 운영체제는 응용 프로그램이 실행되고, 시스템 자원을 사용할 수 있도록 권한과 사용자를 관리한다
응용 프로그램
응용 프로그램은 간단히 말해서, 운영체제를 통해 컴퓨터에게 일을 시키는 역할
→ 이를 위해 컴퓨터를 조작할 수 있는 권한을 운영체제로부터 부여받아야 한다
응용 프로그램이 운영체제와 소통하려면 운영체제가 응용 프로그램을 위한 API를 제공해야 하는데, 응용 프로그램이 시스템 자원을 사용할 수 있도록 다양한 함수를 제공하고 이를 시스템 콜(system call)이라고 부른다
응용 프로그램이 특정 시스템 자원에 대한 권한을 획득한 후에는, 이를 사용할 때 필요한 API를 호출해야 하는데, 이 API가 system call로 이루어져 있는 것
<운영체제 관련 이론: 참고하면 좋을 사이트>
https://parksb.github.io/article/5.html
🦕 공룡책으로 정리하는 운영체제 Ch.1: Overview
Abraham Silberschatz의 Operating System Concepts는 운영체제의 바이블로 불린다. 이번에 운영체제 수업을 들으면서 Operating System Concepts 9th Edition의 내용을 정리해보기로 했다.Ch.1은 책 전체 내용이 담겨있
parksb.github.io
프로세스, 스레드, 멀티 스레드
프로세스(process)
실행 중인 하나의 애플리케이션을 지칭
ex) 웨일 브라우저를 2개 실행하면, 2개의 프로세스가 생성되는 것
→ 하나의 애플리케이션은 여러 프로세스(다중 프로세스)를 만들 수도 있다
간단히 살펴 보면, 작업 관리자 키면 나오는 각 프로세스
스레드(thread)
사전적 의미로 한 가닥의 실
→ 1개의 작업을 실행하기 위해 순차적으로 실행한 코드를 실처럼 이어 놓았다고 유래된 이름
즉, 1개의 스레드는 코드가 실행되는 하나의 흐름
한 프로세스 내에 스레드가 2개라면, 코드가 실행되는 흐름이 2개 생긴다는 뜻
멀티 스레드(multi-thread)
멀티 스레드에 대해 이해하려면 먼저 멀티 태스킹을 알아야 한다
- 멀티 태스킹: 2가지 이상의 작업을 동시에 처리하는 것
→ 운영체제는 멀티 태스킹이 가능하도록 프로세스마다 시스템 자원을 적절히 할당하고 병렬로 실행함
멀티 태스킹이 멀티 프로세스를 의미하는 것은 아니다
→ 1개의 프로세스에서 멀티 태스킹이 가능하기도 함(멀티 스레드)
즉, 정리하자면
- 멀티 프로세스: 애플리케이션 단위의 멀티 태스킹
- 멀티 스레드: 애플리케이션 내부에서의 멀티 태스킹
멀티 스레드는 다양한 곳에서 사용된다
ex) 대용량 데이터의 병렬 처리, 애플리케이션의 네트워크 통신, 서버 개발 등
스레드의 특징
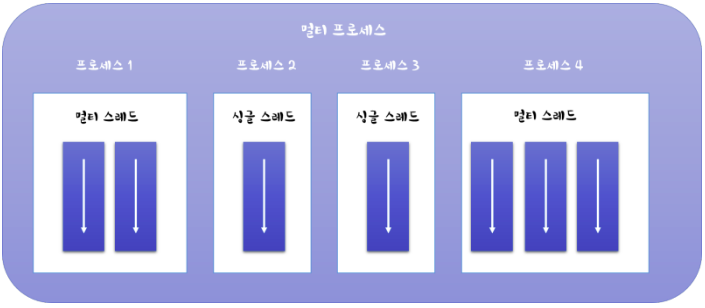 |
* 각 프로세스 내에서 실행되는 하나의 흐름의 단위
* 각 스레드마다 call stack이 존재(call stack: 실행되는 서브루틴을 저장하는 자료 구조)
→ 각 스레드는 프로세스 내에서 각각 stack만 따로 할당 받고 code, static, heap 영역은 공유한다
* 스레드는 각각 독립적으로 동작(다른 스레드와)
멀티 스레딩의 장점
프로세스를 이용하여 동시에 처리하던 작업을 스레드로 구현할 경우, 메모리 공간과 시스템 자원의 소모가 줄어든다
스레드 간 통신 시에도 별도의 자원을 쓰는 것이 아닌, 동적으로 할당된 공간인 heap 을 사용함으로써 프로세스 간 통신 방법(IPC)에 비해 스레드 간 통신 방법이 훨씬 간단
→ 이러한 이유로 시스템의 처리량(throughput)이 향상되고 자원 소모가 줄어들어, 프로그램의 응답 시간이 단축된다
→ 이런 장점으로 여러 프로세스에서 할 수 있는 작업을 멀티 스레드로 작업하는 것(멀티 스레딩)
멀티 스레딩의 문제점(단점?)
멀티 프로세스 기반일 때는 프로세스 간 공유 자원이 없다
이에 비해, 멀티 스레드 기반의 프로세스에서는 공유 자원(heap 영역, 동일 데이터 접근 등)이 존재하여, 프로그래밍할 때 공유 자원에 대한 접근 및 순서 제어가 필요하다
→ 동기화 작업을 통해 공유 자원에 대해 작업 처리 순서 및 접근 제어를 해야 함
교착 상태와 관련 키워드들
앞서 본 멀티 스레딩의 문제점으로 발생할 수 있는 대표적인 것이 교착 상태(데드락)이다
- 데드락(Deadlock; 교착 상태): 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태
→ 주로 공유 자원에 대해서 발생할 수 있는 문제점인데, 이러한 문제점을 해결하기 위한 방법으로
상호 배제를 달성하는 기법이 필요(아래의 기법이 모든 교착 상태에 대한 해법인 것은 아님)
아래의 뮤텍스와 세마포어가 서로 다른 방식으로 상호 배제를 달성하는 기법들
- 뮤텍스(Mutex): 현재의 공유 자원에 들어갈 권한(ex. 키)에 해당하는 어떤 오브젝트가 있고 이 오브젝트(키)를 소유한 스레드(프로세스) 만이 공유 자원에 접근 가능하다
→ 어떤 스레드가 공유자원을 쓰려고 할 때, 그 공유 자원을 다른 스레드가 사용하고 있으면, 그 수행이 끝날 때까지 대기하다가 끝나면, 이제 그 공유자원에 접근하는 것 - 세마포어(Semaphore): 현재 공유 자원에 접근할 수 있는 스레드(프로세스)의 수를 나타내는 카운트 값을 두어, 상호 배제를 달성하는 기법
→ 간단히 말하면 뮤텍스랑 비슷한데, 뮤텍스는 세마포어의 카운트 값이 1인 세마포어라고 보면 된다
동시성과 병렬성의 차이
일반적으로 한번에 동시에 돌릴 수 있는 스레드의 수는 컴퓨터의 CPU 코어 개수로 제한된다
운영체제는 각 스레드를 시간에 따라 분할하여 여러 스레드가 일정 시간마다 돌아가면서 실행되게 한다
→ 시분할 방식
- concurrency(동시성, 병행성): 여러 개의 스레드가 시분할 방식으로 돌아가서 마치 동시에 수행되는 것 처럼 착각을 불러일으킴
- parallelism(병렬성): 멀티 코어 이상 환경에서 여러 개의 스레드가 실제로 동시에 수행되는 것(착각x)
 |
- context switching: 다른 작업(프로세스, 스레드)가 시작될 수 있도록, 이미 실행 중인 작업을 멈추는 것
가비지 컬렉션
가비지 컬렉션이란, 프로그램에서 더 이상 사용하지 않는 메모리를 자동으로 정리하는 기능을 뜻함
→ 자바, C#, 자바스크립트 등이 가비지 컬렉션 기능을 지원한다
가비지 컬렉션의 방법
대표적인 가비지 컬렉션의 방법으로는 트레이싱, 레퍼런스 카운팅이 있다레퍼런스 카운팅 방식이 초기의 단순한 방식이고, 최근에 많이 쓰는 방식이 트레이싱 방식이다
트레이싱(표시하고 지우기)
객체(오브젝트)에 flag를 두고, 가비지 컬렉션 cycle마다 flag에 표시 후에 삭제하는 방법(mark and sweep)
동작 방식을 더 설명하면, 객체에 in-use flag를 두고, 사이클마다 메모리 관리자가 모든 객체를 추적해서 사용 중인지 아닌지를 표시(mark)한다
그 후 표시되지 않은 객체를 삭제(sweep)하는 단계를 통해 메모리를 해제
- 한계점:
수동 메모리 해제를 할 수 없다는 한계가 존재
(때에 따라 어떤 메모리를 언제 해제할 지 수동으로 결정하는 것이 편리할 때가 존재하는데...) - 대표적 예: IE, Firefox, Opera, Chrome, Safari와 같은 최신 브라우저들은 트레이싱 방식으로 가비지 컬렉션을 수행함
- node.js도 크롬 v8 엔진 기반으로 만들어진 플랫폼이므로, 해당 방식으로 가비지 컬렉션을 수행
레퍼런스 카운팅(참조 카운팅)
객체를 참조하는 변수의 수를 추적하는 방법
객체를 참조하는 변수는 처음에는 특정 메모리에 대해 레퍼런스가 1개뿐(1)이지만 변수의 레퍼런스가 복사될 때 마다 레퍼런스 카운트가 늘어 날 것이다(cnt++)
만약, 객체를 참조하고 있는 변수의 값이 바뀌거나, 변수 범위(스코프)를 벗어나면 이 레퍼런스 카운트는 줄어들 것(cnt--)
→ 레퍼런스 카운트가 0이 되면(cnt===0), 그 객체와 관련한 메모리를 비울 수 있을 것이다(메모리 해제 가능)
- 한계점:
순환 참조: 두 객체가 서로 참조하는 것의 한계가 존재한다
→메모리 누수의 흔한 원인
캐시
웹 서비스에서의 캐시
캐시란?
많은 시간이나 연산이 필요한 작업의 결과를 저장해두는 것
캐시는 일반적으로 일시적인(temporarily) 데이터를 저장하기 위한 목적으로 존재하는 고속의 데이터 저장 공간
→ 첫 작업 이후에 이 데이터에 대한 요청이 있을 경우, 데이터의 기본 저장 공간에 접근할 때보다 더 빠르게 요청을 처리할 수 있다(임시 저장한 데이터를 효율적으로 재사용)
일반적인 작동 원리
캐시의 데이터는 일반적으로 RAM과 같이 빠르게 액세스할 수 있는 하드웨어에 저장되고, 소프트웨어 구성 요소와 함께 사용될 수도 있다
→ but, 일반적으로 데이터의 하위 집합을 일시적으로 저장하는 것 뿐이다.
SSD, HDD 같은 기본 저장 장치에 액세스하는 필요를 줄이고, 더 빠른 장치인 RAM을 통해서 데이터 검색의 성능을 높이는 것
캐시의 장점
* 애플리케이션 성능 개선
→ 데이터 읽는 속도가 빨라지므로
* 데이터베이스 비용 절감
→ 단일 캐시 인스턴스는 다른 수많은 DB 인스턴스를 대체할 수 있으므로
* 백엔드의 부하 감소
→ 읽기 로드(부하)의 상당 부분을 인-메모리 계층으로 리디렉션하기 때문에 백엔드 DB의 부하가 감소
* 예측 가능한 성능
→ 갑작스레 애플리케이션 사용량이 증가해도(ex. 블랙 프라이데이) 애플리케이션 성능을 예측할 수 있음
(캐시를 사용하지 않았다면, 데이터를 가져오는 데 있어 지연 시간 증가 및 성능 예측이 불가능해질 것)
* 데이터베이스 핫스팟 제거
→ 애플리케이션에 자주 액세스 되는 부분(데이터)이 존재한다면, 이 부분에 대해 데이터베이스 핫스팟을 발생할 수 있고,
DB 리소스를 초과 프로비저닝해야 할 수 있다
→ 자주 액세스 되는 데이터를 캐시가 담당해서 데이터베이스 핫스팟 발생을 제거할 수 있다는 것
* 읽기 처리량 증가
- 읽기 처리량: IOPS; Input/output operations per second. HDD, SSD 등의 컴퓨터 저장 장치의 성능 측정 단위
→ 읽기 성능이 증가한다는 뜻?프로비저닝(provisioning): 사용자 요구에 맞게 시스템 자원을 할당, 배치, 배포해 두었다가 필요시 시스템을 즉시 사용할 수 있는 상태로 미리 준비해 두는 것
웹 서비스에서 캐시의 사용 예
* 클라이언트:
- 사용 사례: 웹 사이트에서 웹 콘텐츠를 검색하는 속도 가속화
- 사용 기술: HTTP 캐시 헤더, 브라우저
* 네트워크:
1. DNS
- 사용 사례: 도메인과 IP 간 확인
- 사용 기술: DNS 서버
2. 웹
- 사용 사례: 웹 또는 앱에서 웹 콘텐츠를 검색하는 속도 가속화, 웹 세션 관리(서버 측)
- 사용 기술: HTTP 캐시 헤더, CDN(콘텐츠 전송 네트워크; 지리적 제약 없이 전 세계 사용자에게
빠르게 콘텐츠를 전송할 수 있는 콘텐츠 전송 기술), 리버스(역방향) 프록시
* 서버 및 데이터베이스:
1. 앱
- 사용 사례: 애플리케이션 성능 및 데이터 액세스 가속화
- 사용 기술: 키-값 데이터 스토어(ex. Redis: 오픈소스 인-메모리 키-값 데이터 구조 스토어),
로컬 캐시(인-메모리, 디스크)
2. 데이터베이스
- 사용 사례: 데이터베이스 쿼리 요청과 관련한 지연 시간 단축
- 사용 기술: 키-값 데이터 스토어, 데이터베이스 버퍼참고 사이트
https://aws.amazon.com/ko/caching/
캐싱이란 무엇이고 어떻게 작동합니까 | AWS
Internet Explorer에 대한 AWS 지원이 07/31/2022에 종료됩니다. 지원되는 브라우저는 Chrome, Firefox, Edge 및 Safari입니다. 자세히 알아보기
aws.amazon.com
보충 내용
메모리
Windows 운영체제 사용자들 대다수가 한 번쯤을 봤을 x86(32비트) 또는 x64(64비트) 운영체제
이 둘의 차이점을 아주 간단하게 말하자면 비트의 너비(폭). 비유하자면 고속도로에 32개의 차선이 있는데 이를 더 넓혀 64개의 차선으로 만든 것 직관적으로 말하자면 이를 데이터 처리 단위라고 보면 된다
→ 64bit 운영체제가 데이터 처리 단위가 더 많으므로, cpu 처리도 고속화되고 새로운 명령어도 만들 수 있는 것
그런데 이 부분은 메모리와도 연관이 있다
메모리 한 칸은 1byte(8bit)의 크기를 가짐. 그리고. 32비트 운영체제에서는 4byte(32bit) 길이의 주소를 가진다(길이와 크기의 혼동 조심!)
→ 메모리 한 칸의 평수가 1평이고, 이 집을 가리키는 주소가 32자리로 표현된다고 생각하면 편함
1비트는 0,1 로 이루어졌으니깐, 메모리의 주소의 경우의 수는 2^32= 4,294,967,296개
이는 1바이트 크기의 메모리가 2^32개만큼 인식 가능하다는 뜻
→ 즉, 메모리의 최대 크기는 2^32 = 대략 4Gb라는 것(그래서 이론적으로 32비트 운영체제에서는 최대 메모리가 4Gb까지 인식되는 것이다)
메모리의 주소를 표현할 때는 16진법으로 표현함
//
32bit에서는 0x00000000 ~ 0xFFFFFFFF
64bit에서는 0x0000000000000000 ~ 0xFFFFFFFFFFFFFFFF프로그래밍 언어에서
- 포인터(pointer): 메모리 공간 주소를 가리키는 변수
→ 포인터는주소를 가리키기 때문에 운영체제가 몇 비트냐에 따라 그 크기도 달라짐
→ 32bit 체제에서는 4byte, 64bit 체제에서는 8byte의 크기를 가지는 것
텍스트 파일 vs. 이진 파일
* 텍스트 파일
- 사람이 읽을 수 있는 문자(텍스트)로 구성된 파일
- ASCII 코드를 이용하여 저장함
- 연속적인 라인들로 구성되어 있다
- 라인의 끝을 처리하기 위한 개행문자 처리 방식이 운영체제마다 상이( \n, \r 등)
- 컴퓨터에 저장되는 방식: 문자에 해당하는 아스키코드로 변환된 후 그게 다시 binary code로 변환되어 저장됨(문자→ ASCII → BIN)
- 예: 소스 코드 파일, *.txt 등
* 이진 파일(binary file)
- 사람은 읽을 수 없으나 컴퓨터는 읽을 수 있는 파일
- 이진 데이터(0,1)로 구성된 파일
- 이진 파일은 텍스트 파일과는 달리 라인들로 분리되지 않음
- 이진 파일은 특정 프로그램에 의해서만 판독이 가능함
- 컴퓨터에 저장되는 방식: 이진수 형태 그대로 저장됨(BIN)
- 예: 이미지 파일(ex. *.png, *.jpg), 데이터 파일(*.dat), 실행 파일(*.exe), 사운드 파일 등
코드의 작동 순서(with. setTimeout)
function logA() { console.log('A') }
function logB() { console.log('B') }
function logC() { console.log('C') }
logA();
setTimeout(logB, 0); //setTimeout 은 비동기 함수
// delay 인자가 0인 경우, “즉시”; 정확히 말하면, 다음 이벤트 사이클에 실행한다는 뜻
logC();위 코드를 살펴 보면,
logA, setTimeout, logC 작업이 call stack에 순서대로 push된다
setTimeout 호출 시, logB 작업은 task queue에 enqueue 되고,
logC의 실행이 완료되고 call stack에 아무 작업도 남지 않으면, event queue의 head에 있는 logB 이벤트가 call stack에 push 된다
→ 그러므로, 출력 결과는 A, C, B의 순서로 출력된다
'SE Bootcamp 내용 정리' 카테고리의 다른 글
| 네트워크 - 심화(프로토콜 계층, HTTP 헤더, 웹 캐시) (0) | 2021.11.30 |
|---|---|
| 컴퓨터 공학 - 핵심 내용 정리 (0) | 2021.11.26 |
| 인증/보안 - OAuth 인증 구현 (0) | 2021.11.26 |
| 인증/보안 - 기초 2: CSRF, Token (0) | 2021.11.25 |
| 인증/보안 - session 기반 인증 구현하기 실습 (0) | 2021.11.25 |